





 课程介绍册
课程介绍册 申请指南
申请指南

地表最强 AI 模型 GPT-4 来了!如何影响现有世界?
OpenAI 的新“核弹”来了。
3 月 14 日晚间,OpenAI 宣布发布 GPT-4。
OpenAI 联合创始人 Sam Altman 表示,它是“迄今为止功能最强大、最一致的模型”,能够使用图像和文本。
GPT-4 的表现已经远远超过了前辈 ChatGPT。它不仅能在十秒钟制作一个网站,而且在各大考试中,它几乎都取得了满分成绩。此外,GPT-4还有一个质的飞跃:能看懂一张图片背后的隐含内容。
两天之后,微软宣布,GPT4全面植入Office办公软件。Word、Excel、PPT之类的办公软件互通,GPT-4穿梭其中。这意味着我们与电脑的交互方式迈入了新的阶段,从此我们的工作方式将永远改变,开启新一轮的生产力大爆发。
GPT 模型究竟厉害在哪里?又有哪些不足?Open AI 是一家怎样的公司?在AI生成内容领域(AIGC),目前国内与国际上的距离还有多远?未来,怎样的岗位是可以被替代掉的?
本场F-Talk由连星资本投资总监、中欧FMBA2022级同学赵杨博发起,邀请聆心智能联合创始人郑叔亮,Versa创始人兼CEO、中欧创业营10期学员蔡天懿与您共同分享。
1、大型语言模型 GPT 是什么?
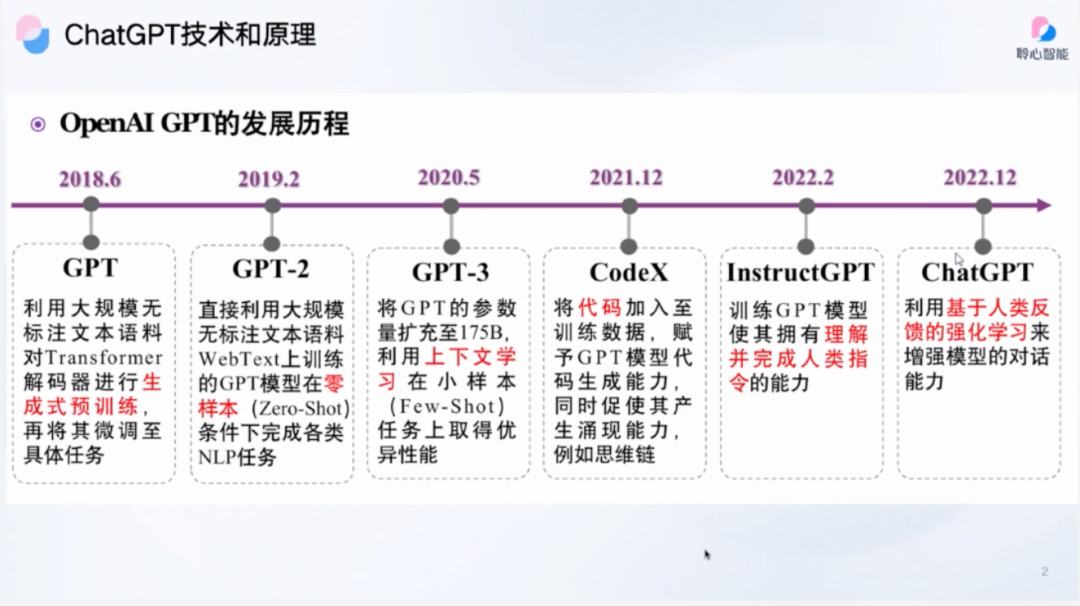
郑叔亮:GPT(Generative Pre-training Transformer),指的是生成性预先训练转换器,GPT是一种自然语言处理模型,也是一种大型语言模型(LLM)神经网络。
大型语言模型使用一种称为深度学习的技术来生成,看起来像人类生成的文本,可以执行各种自然语言处理任务,例如回答问题、总结文本甚至生成代码行。上下文学习、思维链以及指令学习,这三种类型的技术是现在大模型通常所具备的技术。
OpenAI从2018年到现在的几次关于大语言模型的重要突破,从GPT1.0的版本到2、3,到现在的ChatGPT。其中比较具有里程碑意义的就是2020年发布的GPT-3,它首次提出了超大规模预训练语言模型,这个时候它的参数量达到了1750亿的参数。
在模型参数一般情况下达到了70-80亿,或者说接近百亿的时候,它就会带来比较强的涌现能力,可以出乎人类意料之外地去生成一些相应的对话内容。
2、ChatGPT 厉害在哪里?
郑叔亮:此时此刻的ChatGPT更多像是一个所谓的通用任务助理,在一个模型当中包含了一系列的非传统性的开放任务,这种方式全面革新了AI与人进行交互的一种方式,我们说它带来了一种全新的AI交互范式。
我们只需要一个非常简单的对话窗口就可以,你只要把你的需求/要求阐述足够清楚,它就可以帮助你非常好的完成一些相关指令性的任务,所以它在整个开放性任务上表现得非常惊艳。当然了,这在很大程度上其实取决于ChatGPT团队在背后对于任务本身数据的大规模非常繁杂非常细致的工作,才有了它现在这样的效果。

3、ChatGPT 厉害在哪里?
郑叔亮:ChatGPT存在的问题主要是事实性错误,即回答中存在幻觉,这是因为它是基于统计学理论构建的自回归生成式模型,在生成每一个文字或Token时都要参考之前生成的内容和用户的输入,因此经常会用非常流畅的表达方式编造一些事实,导致回答存在事实性错误。
这种问题在医疗、司法公正和金融等严肃场景中应用会受到限制,因为它可能会给人以假乱真的假象。此外,由于ChatGPT背后的语言模型是基于大量文本数据训练的,因此它的回答可能会受到语料库的限制,缺乏对实际场景的理解和判断。此外,ChatGPT还存在数据隐私和安全性等问题,因为其需要使用大量用户数据进行训练,可能会暴露用户隐私。
4、什么是AIGC?
蔡天懿: 能做的事情不局限于刚才说到的,它正进入一个更广阔的领域 AIGC。所谓AIGC,就是利用人工智能技术来生成内容。如今,它不仅备受资本界的青睐,而且在消费者中人气也颇高。比如,从去年年底开始,AI 绘画就火爆出圈,风靡社交网络。只需要输入文字指令,AI 就能一键生成你想要的绘画作品。而 AI绘画、AI对话、AI写作…都属于 AIGC 的分支。不过,目前在国内,中国的市场上,AIGC是个全新的东西,并没有形成完整的生态链的环境。
5、Open AI是一家怎样的公司?它的融资模式是怎样的?
蔡天懿: OpenAI是一个非盈利的人工智能研究公司,它创立就是这么做的,它本质上就是要做AGI。但是这个公司有非常强的愿景,它说关注长期安全,如果一个与人类价值观相符,注重安全的项目领先于我们,达成通用人工智能,我们承诺将竞赛结束,转而去协助这个项目。两个竞品,比我们做的好,我把我并给你,这是他们的公司章程。这是美国企业家的样子,是这四个人建的,分别是马斯克、Reid Hoffman,Reid Hoffman是领英的老板,Peter Thiel是Paypal的老板,这三个人就是paypal mafia,最重要的几个人。这些人本质上没有资本可以裹挟他们,没有人可以裹挟他们,国家也不能阻碍他们,甚至人类也不能阻碍他们,定出来的标准特别浪。
我特别要说一下Sam Altman,他是YC的总裁,YC其实是美国最大的孵化器,非常像中国的真格。Sam给OpenAI建立了一个全新融资模式,首先Sam自己在里面没有任何持股,他就是想把这个东西弄好。
第一个阶段,先把之前的投资人清出去,好像大部分的并购都是这样。第二部分,微软将有权获得OpenAI75%的利润,直到收回130亿的投资。这是一个赚钱机器,微软要赚钱,OpenAI75%的利润,把投资收回去。当利润达到920亿以后,微软在该公司的持股比例将下降到49%。大家发现很有意思的一件事情,现在没到第三阶段,到第三阶段才是49%,现在属于谁了?坦率说你问我现在它属于谁,没有那个数据说出来,但是它说下降到49%,我认为它今天就是属于微软的。剩余49%将奉献给其他投资人和OpenAI。利润达到1500亿以后,微软和其他投资人将将股份还给OpenAI的organization。
大家看到Sam的智慧吗,简单来说世界上最牛的科技创业者都在卖身,你在刚什么呢。如果达成这个目的,就继续还给这个组织,但是我现在做不成,我要钱,那我卖身就卖。对大量的科技创业者来说能不能做成这件事比自己能拿多少钱可能重要得多。

6、做大语言模型最大的阻碍是什么?
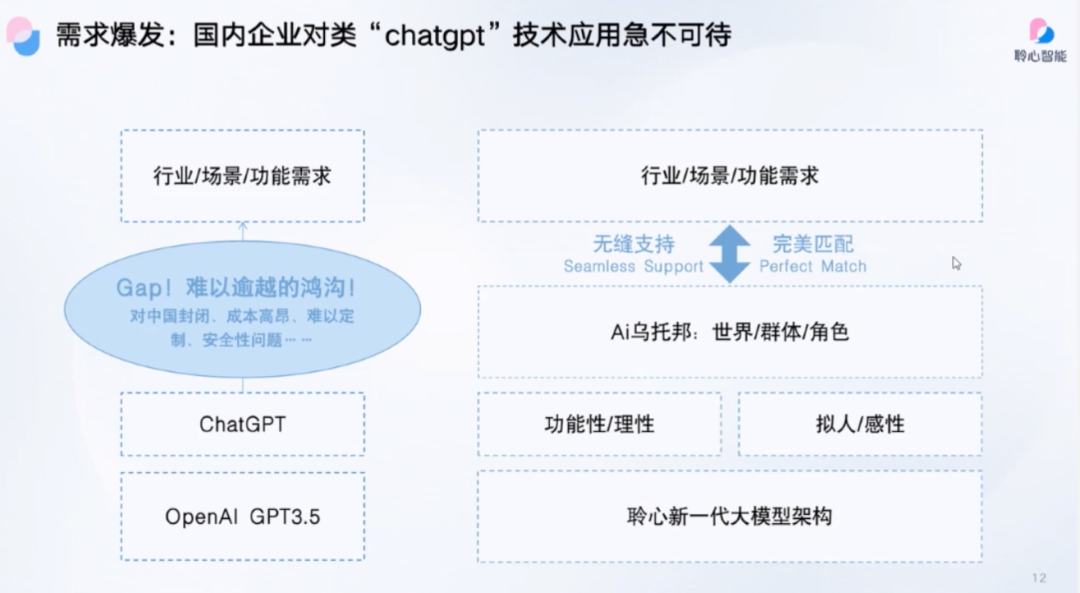
郑叔亮:做大语言模型最大的阻碍是算力和数据。在算力方面,技术被卡脖子,国家整体算力资源紧俏,预计将越来越紧俏。而在数据方面,互联网上可挖掘的数据已经很多,进一步优化模型所能挖掘的东西不足,因此需要花费很大的力气编制数据,并通过各种手段和方法来造出更有质量的数据。优质的数据资源能够快速有效地补充到模型中来,让大模型底座变得更加强健,性能变得更好,更加能够适应专业化场景。因此,数据资源是现在面临的一个挑战,需要投入大量的资源来解决和攀登。在其他方面,如技术和算法,公司还是很有自信的。
7、中国在AIGC的技术与国外差距在哪里?最应该补足在哪一个地方?
蔡天懿:中国在AIGC技术方面的差距主要体现在算力和数据采集上,而算法方面并没有明显劣势。他提到,OpenAI在算法布局上非常好,但中国也有足够多的杰出人才可以做好算法。相反,中国需要在算力和数据采集方面加大投资,才能缩小与国外的差距。如果有一个CEO能够搜集好微博、知乎、百度等各种数据,并找到浦江实验室等超算中心提供算力,投入数十亿进行研发,中国就可以追赶上国外。因此,中国最应该补足的是算力和数据采集方面的投入。
中国的科技实力在不断变化。中国目前不是技术方面的瓶颈,而是投资和数据方面的瓶颈。因此,如果中国能够大力投资算力和数据采集,就能够缩小与国外的差距。在我看来,站在自己的视角,中国的科技一定不会落后。

郑叔亮:在AIGC领域中,中国与国外存在巨大的技术差距。中国不缺乏创新性人才,但是系统技术的发展需要产业化和集群的支持。中国大型互联网平台公司应该愿意分享数据、库存的高性能显卡等资源,一起研究开发大模型,提高技术水平和性能。然而,中国缺乏体系结构的研究,包括芯片、操作系统、中间件等基础技术都依赖国外公司,例如英伟达的显卡、CUDA的中间件、Linux的操作系统等。中国的国产化芯片性能也不如上一代产品,因此很难被直接使用。中国需要在技术上进行弯道超车,发力推进体系结构的研究,缩小与国外的技术差距。







